Node.js for the enterprise !
Introduction
Once I was annoyed by a novice question regarding how my phone worked, shared that thought with a friend at work who smiled kindly and reminded me that "We are all a bunch of dinosaurs roaming the mobile land", I do tend to disagree as most of the concepts we are dealing with today are actually not new at all, but I digress.
So, as someone who considers himself a master of the old world of legacy web apps I decided to explore how the new kid on the block (Node.js) respond to my Mesozoic Era standards (that is the era when dinosaurs lived if you are wondering).
The first of this series is going to go through a quick configuration to run Node.js over HTTPS using self signed Cert, but first let us understand why do we want to do that (there are good reasons for doing that , trust me).
DMZ, SSL and those nasty security checks
A few years back I worked with a brilliant (also neurotic) application server administrator that was adamant about turning off all HTTP traffic to his application servers farm.
"Only HTTPS is allowed" , "HTTP is for welcome page, go get that 'bleeb' of a web server not from my App Server".
He was right, this is the typical layout of an Enterprise Application server
Using firewalls to protect enterprise application server.
A potential hacker will have no access to any of application servers directly but rather has to go to perimeter we call DMZ zone, If by any chance he gained access to any of the servers in that zone he must not have any 'powerful tools' under his command. which will leave him stranded until the security team discover and deal with the breach.
This is why the DMZ zone will have computers with very limited abilities, no JVM's, and definitely no Node.js, a proxy gateway like Nginx or even a simple HTTP server like Apache would be safe to put there. those servers are usually 'hardened' i.e. only minimal required software is installed and only minimal required ports are open, so no telnet and some extreme cases no ssh even, you have to physically be in the room to upload files into this machine.
But there is something wrong with this picture, the fact that the Traffic between Nginx and the Node.js servers, the fact it is done in HTTP is a security breach.
Take a close look at the problem
It is the 'Admin' problem, any administrator of those machines can install a network sniffer (wire shark anyone !), and voila , he has access to all unencrypted data going in and out of the servers, that is user names, birth dates, addresses, social insurance numbers, account numbers , anything that the user does submit that is not encrypted.
I have seen many customers forgo using HTTPS internally siting the data is in the "Trusted Zone", I quickly ask the question my security mentor asked me once "Is your company policy such that your server administrator can view the birth dates and social insurance numbers of all your employees" ? while they figure out the answer to this question, we start configuring HTTPS.
Unlike external HTTPS, internal HTTPS does not require a publicly signed and trusted certificates (those are costly and are not easy to obtain). for internal it is sufficient to use self signed certificates, the ones that administrators can create easily and renew at well.
Now you understand the method behind my madness, Node.js should run always in HTTPS and if possible exclusively on HTTPS , So make it a good practice to configure Node.js with HTTPS all the time after all, it will only take you 5 minutes as you see below.
Configuring Node.js for HTTPS
HTTPS is HTTP over SSL, explaining SSL is beyond the scope of this post and to be honest only one man explained to me well 10 years ago (that was the mentor of my security mentor), and I am always amazed at how little understood such a widely used concept.
So in order to configure HTTPS you will need a pair, of keys that is, it is actually a Key and a certificate, the certificate is what your server will present to browsers, if the client (or user) choose to trust your certificate (i.e. trust your server) then they will upload the public key from your site into their end and use that key to encrypt messages that only your site can decrypt using the private key.
In this sample I used the name 'klf' as my organization name to configure my keys so you can use whatever your project name is, I am also using openssl which is an open tool to generate keys, I find it much easier to use for Node.js , when it comes Java servers keytool is a more suitable tool.
1 - Create the Key pair
First you create your private key this way.
openssl genrsa -out klf-key.pem
2 - Create a signature request
openssl req -new -key klf-key.pem
-out klf-csr.pem
This command will ask you a few questions to identify your server (you can see my sample replies in the following screen shot), note I used the password 'passw0rd' I am hoping you have more sense than to do that :).
3 - Self sign that request
openssl x509 -req -in klf-csr.pem -signkey klf-key.pem -out klf-cert.pem
4 - Export the PFX file
Now that you have that self signed certificate , you will need to export the PFX file that you can use in your Node.js to start your HTTPS server
openssl pkcs12 -export -in klf-cert.pem -inkey klf-key.pem -out klf_pfx.pfx
You will be asked to specify your pfx password (I used passw0rd again to make writing this post simple, please use something else !), this will be needed by your Node.js code as you will see in the next step.
5 - Start your Node.js server
Here is the code snippets necessary to start your Node.js (I am using Express here , and this is not all the code, this is just what you need to modify in your express(1) app.js
app.set('port', process.env.PORT || 3000);
app.set('ssl_port', process.env.SPORT || 3443);
var https = require('https');
var fs = require ('fs');
var options = {
pfx : fs.readFileSync('ssl/klf.pfx'),
passphrase : 'passw0rd',
requestCert : false
} ;
https.createServer(options,app).listen(app.get('ssl_sport'), function(){
console.log('Express server listening on SSL' + app.get('sport'));
});
6 - Start the server and test from a browser
Next you need to access your server using https://localhost:3443 .
Your browser will likely warn you against the certificate (because the browser does not see any signing authority on it) so tell the browser to trust it.
You can click 'Show Certificate' and you will see that Node.js is presenting you with the certificate that you have self signed
Conclusion
Using Nginx or any other HTTP router to terminate SSL request that will be using a publicly signed certificate and initiate a second SSL request from the DMZ to the Node.js in the corporate trusted zone is a good practice for on premise enterprise Node.js applications.
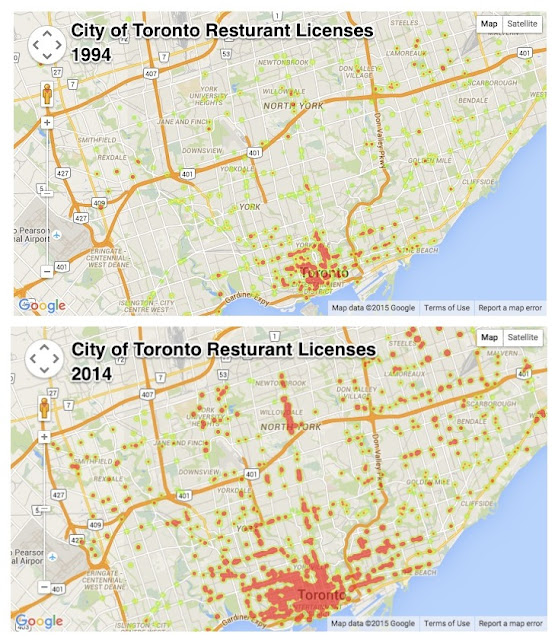
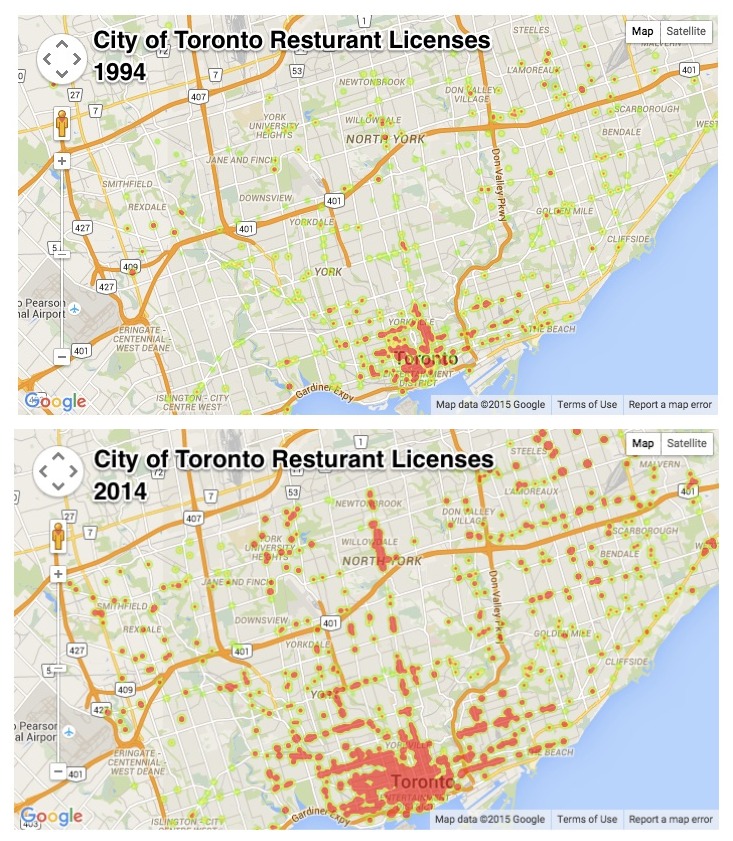


 Another file we will need is a file that contains all Canadian Postal Codes and their Latitude and Longitude (I contemplated using google maps API's but the sheer number of Postal code calls made me realize I will run my 2400 calls per day quota in no time).
Another file we will need is a file that contains all Canadian Postal Codes and their Latitude and Longitude (I contemplated using google maps API's but the sheer number of Postal code calls made me realize I will run my 2400 calls per day quota in no time).

















.png)

